Marco Kuznik
May 7, 2024
KI für kleine und mittelständische Unternehmen
KI Themen wie Large Language Models, Video Generierung oder Reinforcement Learning werden von den großen Tech Companies dominiert. Sie werfen neue riesige Modelle im Tagesrhythmus auf den Markt. Die Modelle werden mit teuren GPUs hunderte bis tausenden von Stunden trainiert. Die Kosten, die dabei anfallen, sind exorbitant und für ein normales Unternehmen kaum zu stemmen. In diesem Artikel zeigen wir, welche Möglichkeiten es für kleinere Unternehmen gibt, am KI-Boom zu partizipieren. Wir gehen dafür zunächst auf die Grundlagen von KI ein und zeigen dann konkrete Anwendungsmöglichkeiten und wie auch mit geringeren Kosten schon großartige Ergebnisse möglich sind.
Grundlagen
KI steht für Künstliche Intelligenz (engl. AI = Artificial Intelligence). KI ist ein Oberbegriff für Technologien, die es Maschinen ermöglichen, menschenähnliche Aufgaben zu erledigen. Ein Teilbereich der Künstlichen Intelligenz ist das Maschinelle Lernen (engl.: Machine Learning). Maschinelles Lernen mit statistischen Verfahren bildet die Grundlage für viele KI-Anwendungen. Darauf aufbauend gibt es das Maschinelle Lernen, welches sich auf neuronale Netze mit wenigen Schichten und Neuronen stützt. Im Unterschied zu den statistischen Methoden werden die Modelle und Muster nicht explizit programmiert. Beim Maschinellen Lernen wird ein neuronales Netz erstellt, mit dem man Vorhersagen aus Daten machen kann, die das Netz zuvor noch nicht gesehen hat. Das Netz lernt Ähnlichkeiten zu erkennen und darauf aufbauend eine Vorhersage zu machen.
Ein neuronales Netz könnte wie folgt aussehen:
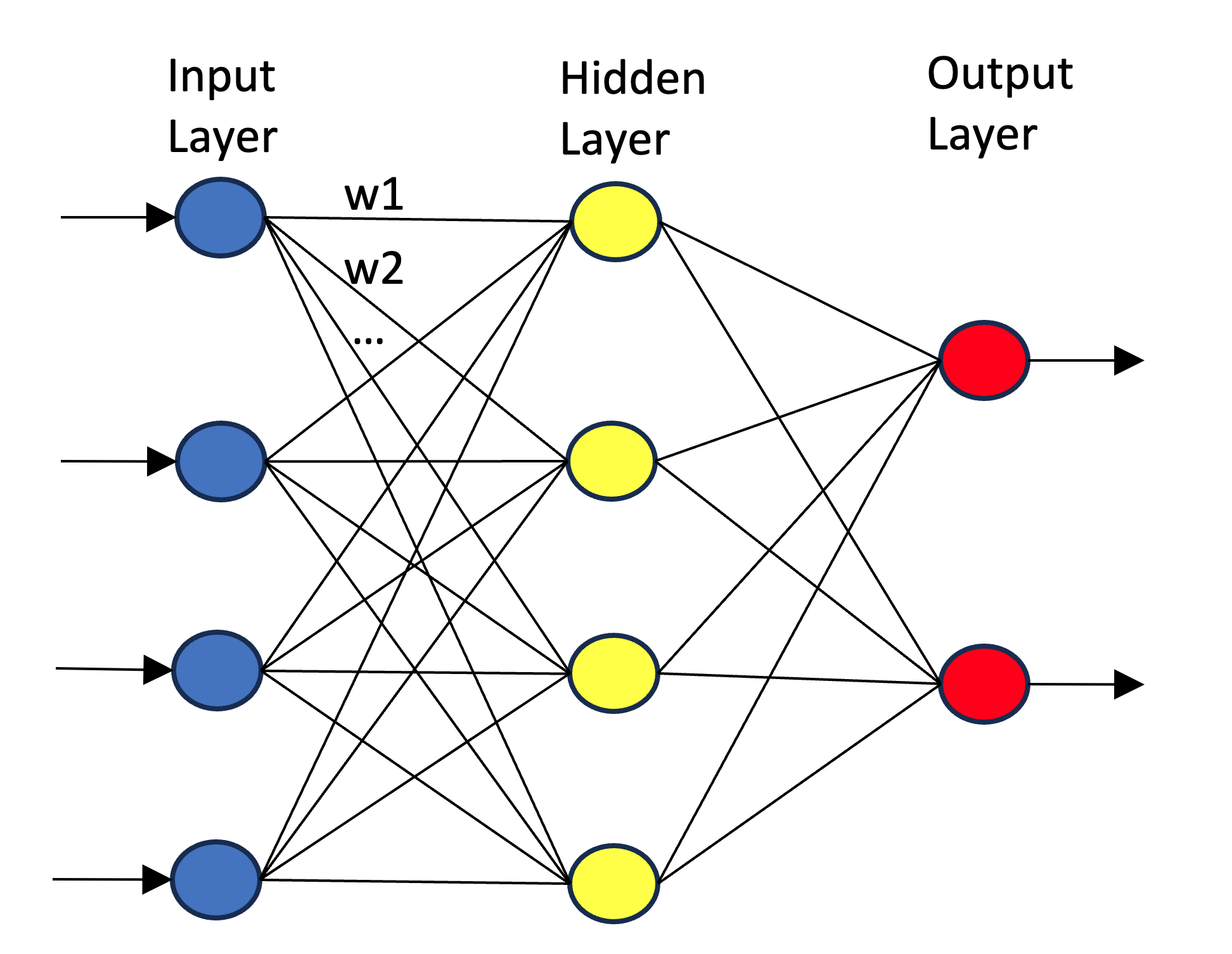
Es ist ein computergestütztes Modell, das von der Funktionsweise des menschlichen Gehirns inspiriert ist. Es besteht aus einer Reihe von Knoten, auch Neuronen genannt, die in Schichten angeordnet sind: einer Eingabeschicht, einer oder mehreren versteckten Schichten und einer Ausgabeschicht. Jedes Neuron in einer Schicht ist mit mehreren Neuronen der nachfolgenden Schicht über sogenannte Gewichte (in der Abbildung oben w1, w2, …) verbunden, die im Trainingsprozess angepasst werden.
Die Eingabeschicht empfängt die Daten, die dann durch das Netzwerk fließen, wobei jedes Neuron eine gewichtete Summe seiner Eingaben berechnet, die durch eine Aktivierungsfunktion geleitet wird, um die Ausgabe des Neurons zu bestimmen. Diese Ausgaben werden dann an die nächste Schicht weitergegeben, bis die Ausgabeschicht erreicht ist, die die endgültige Vorhersage oder Klassifikation liefert.
Neuronale Netze sind besonders mächtig in der Erkennung von Mustern und werden daher in vielen Bereichen wie Bild- und Spracherkennung, Spieleentwicklung, Finanzwesen und Medizin eingesetzt, um komplexe Probleme zu lösen, die für traditionelle algorithmische Ansätze schwer zugänglich sind.
Deep Learning ist ein Teilbereich des maschinellen Lernens, der sich auf den Einsatz tiefer (d.h. mehrschichtiger) neuronaler Netzwerke spezialisiert. Diese Netzwerke sind so konzipiert, dass sie große Mengen an unstrukturierten Daten lernen und interpretieren können, um komplexe Muster zu erkennen und Entscheidungen nahezu autonom zu treffen.
Ein tiefes neuronales Netzwerk besteht aus viele versteckten Schichten zwischen der Eingabe- und der Ausgabeschicht. Jede Schicht lernt unterschiedliche Merkmale auf unterschiedlichen Abstraktionsebenen. Zum Beispiel kann in der Bilderkennung die erste Schicht einfache Merkmale wie Kanten erkennen, während tiefere Schichten komplexere Merkmale wie Gesichter oder Objekte identifizieren.
Der Lernprozess in neuronalen Netzen erfolgt durch Fehlerrückführung (Backpropagation) in das Modell, was es ihm erlaubt, sich durch iterative Anpassung der Gewichte zwischen den Neuronen auf Basis des Fehlergrades der Ausgaben zu verbessern. Dabei wird eine Verlustfunktion verwendet, die den Fehler zwischen der tatsächlichen Ausgabe und der vom Netzwerk vorhergesagten Ausgabe misst. Durch diesen Prozess lernt das Netzwerk, wie es seine internen Parameter einstellen muss, um genaue Vorhersagen oder Klassifikationen durchzuführen. Eine Vorhersage ist das Ergebnis eines Modells, das zukünftige, oft kontinuierliche Werte auf Basis vorhandener Daten schätzt. Im Gegensatz dazu ist eine Klassifikation der Prozess, bei dem ein Modell Datenpunkte auf Basis ihrer Merkmale in vordefinierte kategorische Klassen einordnet, z.B. werden Bilder von Tiere in die Klassen Hunde, Katzen, Pferde, usw. unterteilt.
Deep Learning hat bedeutende Fortschritte in vielen Bereichen ermöglicht, einschließlich der Sprachverarbeitung (z.B. automatische Übersetzungen und Spracherkennung), der Bilderkennung (z.B. Gesichtserkennung und automatische Bildklassifizierung) und der autonomen Fahrzeugsteuerung. Systeme lernen aus großen Datenmengen und treffen intelligente Entscheidungen in Echtzeit.
Nachdem wir die Funktionsweise und die Fähigkeiten von Machine Learning und Deep Learning betrachtet haben, wollen wir nun die Unterschiede zwischen beiden Bereichen genauer beleuchten. Dieser Vergleich hilft uns zu verstehen, warum bestimmte Techniken in verschiedenen Szenarien bevorzugt werden und wie sie sich in ihrer Komplexität, ihrem Ressourcenbedarf und ihren Anwendungsbereichen unterscheiden.
Unterschiede zwischen Machine Learning und Deep Learning
| Machine Learning | Deep Learning | |
|---|---|---|
| Modell Tiefe | niedrig bis mittel | groß |
| Trainingsdaten | wenige bis mittel | sehr viele |
| Hardware Anforderungen | gering | groß, grade im Hinblick auf GPUs und TPUs |
| Laufzeit | wenige Minuten bis Stunden | Wochen bis Monate |
| Interpretierbarkeit | Dies hängt stark von den verwendeten Algorithmen ab, z.B. sind Entscheidungsbäume leicht zu interpretieren wohingegen andere Algorithmen fast nicht interpretierbar sind. | Schwer zu interpretieren oder sogar unmöglich |
Die Übersichtstabelle zeigt, dass Deep Learning Modelle sehr aufwendig zu trainieren und verwenden sind, da sie sehr große Datenmengen benötigen und sehr rechenintensiv sind. Große Modelle, welche viele Parameter enthalten zu erstellen, kostet viel Zeit und Geld. Sehr große Unternehmen oder gut ausgestattete Start-ups können die benötigten Ressourcen meist aufbringen. Für kleine und mittelständische Unternehmen ist dies jedoch nicht so einfach möglich. Zum Glück gibt es für kleinere Unternehmen jedoch einen Mittelweg und sogar einige Abkürzungen, auf die wir im folgenden Abschnitt eingehen.
Methoden des Maschinellen Lernens
Supervised Learning
Hierbei versucht der Algorithmus oder das Modell aus Daten eine Zielvariable vorherzusagen, z.B. eine Klassifikation aus Bildern von Tieren. Für ein Bild von einer Katze wird die Klasse Katze vorhergesagt oder von einem Kommentar auf einer Webseite welcher Stimmung dem Kommentar zu Grunde liegt (Freude, Genuss, Liebe, Überraschung, Hass, Angst, etc). Zumeist handelt sich beim Supervised Learning um Klassifikation oder Regression. Bei der Klassifikation wird eine Kategorie oder Klasse vorhergesagt, bei der Regression ein numerischer Wert.
Unsupervised Learning
Beim Unsupervised Learning gibt es keine Zielvariable. Der Algorithmus versucht Muster in den Daten zu finden. Ein Beispiel ist die Segmentierung von Kunden in Gruppen, die sich ähnlich verhalten. Es gibt mehrere Methoden des Unsupervised Learning, wie
- Clustering
- Association
- Dimensionality Reduction
Beim Clustering werden Gruppen von Daten gebildet, die sich ähnlich sind. Beim Association Learning werden Assoziationen zwischen Daten gefunden, z.B. Kunden die Produkt A kaufen, kaufen auch Produkt B. Bei Dimensionality Reduction werden die Daten so transformiert, dass sie weniger Dimensionen haben, aber die wichtigen Informationen erhalten bleiben. Z.B. können Bilder in Matrizen oder Vektoren gewandelt werden, welche nur die wichtigsten Informationen (Features) enthalten.
Reinforcement Learning
Reinforcement Learning ist eine Methode des Maschinellen Lernens, bei der ein Agent in einer Umgebung agiert und durch Interaktion mit dieser Umgebung lernt, wie er seine Aktionen optimieren kann, um ein bestimmtes Ziel zu erreichen. Der Agent erhält Feedback in Form von Belohnungen oder Bestrafungen für seine Aktionen, die ihm helfen, seine Strategie zu verbessern und bessere Entscheidungen zu treffen. Ein Beispiel für Reinforcement Learning ist die Lagerhaltungskosten Minimierung bei gleichzeitiger Deckung der Nachfrage nach Produkten, um Umsatzausfälle zu vermeiden. Die Herausforderung besteht darin, den idealen Zeitpunkt und die Menge für die Nachbestellung von Produkten zu bestimmen, unter Berücksichtigung von Faktoren wie Lieferzeiten, Lagerkapazitäten, Verderblichkeit der Waren und Nachfrageschwankungen. Der Agent trifft Entscheidungen über Bestellungen basierend auf der Umwelt, die das Lager, die Lieferkette und die Marktnachfrage umfasst, führt Aktionen wie das Bestellen unterschiedlicher Produktmengen durch, bewertet den Zustand anhand aktueller Lagerdaten und historischer Verkaufszahlen, erhält Belohnungen für effiziente Lagerhaltung und lernt kontinuierlich, um die Kosten zu minimieren und die Lieferbereitschaft zu optimieren.
Transfer Learning
Transfer Learning ist eine Technik des Maschinellen Lernens, bei der ein Modell, das auf einer bestimmten Aufgabe trainiert wurde, auf eine andere, ähnliche Aufgabe übertragen wird. Dies ermöglicht es, die Trainingszeit und -ressourcen zu reduzieren und die Leistung des Modells zu verbessern, indem es bereits gelernte Merkmale und Muster auf die neue Aufgabe anwendet. Transfer Learning ist besonders nützlich, wenn die neue Aufgabe nur über begrenzte Trainingsdaten verfügt oder wenn die Trainingsdaten für die neue Aufgabe nicht verfügbar sind. Ein Beispiel für Transfer Learning ist die Verwendung eines vortrainierten Bilderkennungsmodells, das auf einem allgemeinen Datensatz trainiert wurde, um spezifische Objekte in einem neuen Datensatz zu erkennen, der nur begrenzte Beispieldaten enthält.
Semi-Supervised Learning
Semi-supervised learning ist eine Technik des Maschinellen Lernens, bei der ein Modell sowohl mit gelabelten als auch ungelabelten Daten trainiert wird. Dies ermöglicht es dem Modell, aus den gelabelten Daten zu lernen und dieses Wissen auf die ungelabelten Daten zu übertragen, um bessere Vorhersagen zu treffen.
Self-Supervised Learning
Self-Supervised Learning ist eine Technik des Maschinellen Lernens, bei der ein Modell sich selbst beibringt, indem es aus den vorhandenen Daten lernt, ohne dass ein externer Lehrer oder Annotator die Daten für das Training kennzeichnet. Dies ermöglicht es dem Modell, Muster und Merkmale in den Daten zu erkennen und zu generalisieren, um bessere Vorhersagen zu treffen.
OpenAI, Anthropic und Co
Natürliche haben wir immer die Möglichkeit die Modelle von OpenAI (ChatGPT) und ihren Konkurrenten zu nutzen. Wir können diese Modelle sogar durch Feintuning auf unsere spezifischen Daten anpassen. Über die API der großen Anbieter hat man schnell Zugriff auf große Modelle, jedoch zu einem relativ hohen Preis und mit dem Nachteil, dass man seine Daten in die jeweilige Cloud laden muss. Darüber hinaus ist der eigene Wissenszuwachs im Bereich KI relativ gering.
Anpassen von Modellen
Ein weiterer Weg, um KI für kleine und mittelständische Unternehmen zugänglich zu machen, ist die Anpassung von vortrainierten Modellen. Vortrainierte Modelle sind Modelle, die bereits auf großen Datensätzen trainiert wurden und aufgrund ihrer Größe und Komplexität in der Lage sind, allgemeine Muster und Merkmale zu erkennen. Diese Modelle können dann auf spezifische Aufgaben oder Domänen angepasst werden, um genaue Vorhersagen oder Klassifikationen zu treffen. Im Internet gibt es tausende von vortrainierten Modellen, welche man auf die lokale Infrastruktur laden und verwenden kann. Eine Plattform auf der viele Sprachmodelle zu finden sind, ist Huggingface. Man findet dort sowie auch auf anderen KI-Börsen viele frei zugängliche Modelle. Unternehmen wie Google oder Meta haben einen Teil ihrer Modelle frei zugänglich gemacht. Es gibt zwei grundsätzliche Methoden vortrainierte Modelle für eigene Anwendungen anzupassen:
- Feature Extraction
- Feintuning
Beim Feature Extraction können wir die verborgenen Zustände der Modelle als Features für unser eigenes Modell nutzen. Dabei ‘friert’ man die Gewichte des vortrainierten Modells ein. Während des Trainings verwendet man die Features, um einen Klassifikator zu trainieren. Den Output Layer des vortrainierten Modells schneiden wir quasi ab. Dieser Ansatz ermöglicht es, die Vorteile eines vortrainierten Modells zu nutzen, ohne von Grund auf neu trainieren zu müssen. Der Feature Extraction Ansatz ist darüber hinaus kostengünstig und spart Zeit, da nur ein relativ kleines Klassifikationsmodel trainiert werden kann. Dafür muss man mit einer geringeren Leistung leben, die jedoch für viele Anwendungsfälle völlig ausreichend ist.
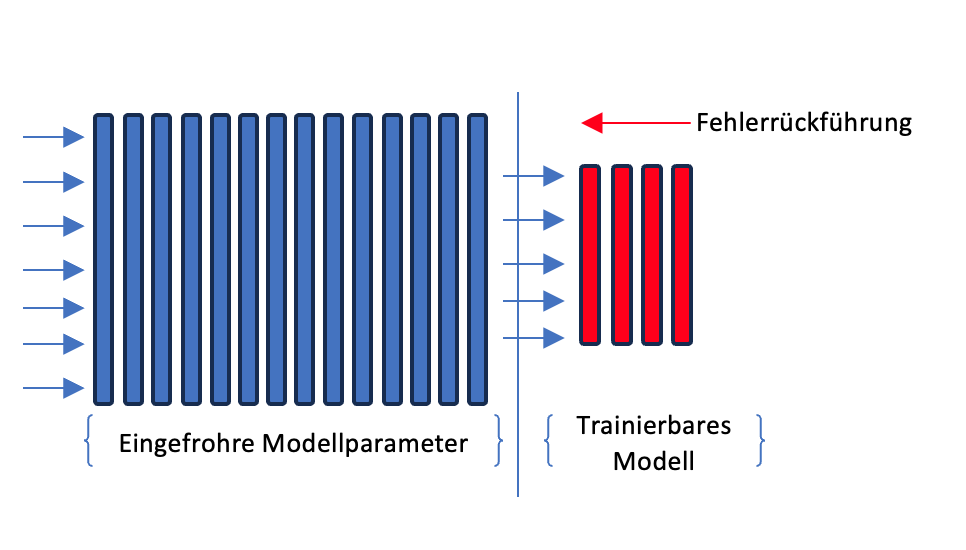
Wir können Modelle aber auch feintunen, also die Gewichte des gesamten Modells anpassen, um spezifische Aufgaben zu erfüllen, das ich an dieser Stelle die Modell Architektur sehr stark vereinfacht dargestellt habe. Bei den meisten Sprachmodellen handelt es sich um Transformer Architekturen. Bei bildverarbeitenden Modellen werden häufig Convolutional Neural Networks (CNN) verwendet. Es gib jedoch eine große Auswahl an Modell-Architekturen und immer wieder Verbesserungen und neue Modelle. Hier wollen wir uns jedoch zunächst auf die grundlegenden Konzepte beschränken.
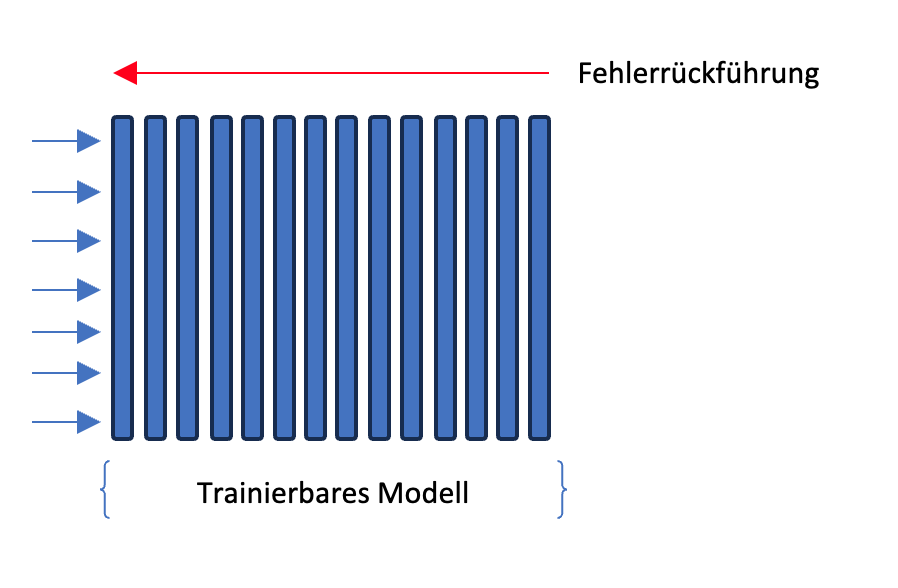
Beide Methoden haben ihre Vor- und Nachteile. Zum einen bietet das Feature Extraction Layer eine schnellere Anpassung an spezifische Daten, da nur ein Teil des Modells angepasst werden muss. Auf der anderen Seite kann das Feintuning bessere Ergebnisse erzielen, da das gesamte Modell auf die spezifischen Daten des Unternehmens abstimmt. Die Wahl der Methode hängt von den Anforderungen und Zielen ab. Es ist mit beiden Methoden möglich gute bis sehr gute Ergebnisse zu erzielen.
Small Language Models
Seit 2023 hat sich der Trend zum Einsatz von Small Language Models wieder deutlich verstärkt. Diese Modelle sind auf einen sparsameren Ressourcenverbrauch ausgelegt, was vor allem durch eine Reduzierung der Modell-Parameter bewirkt wird. Die Parameter eines Modells sind die internen Konfigurationen, die während des Trainingsprozesses modifiziert werden, um das Modell auf die vorliegenden Daten und Aufgaben abzustimmen. Die Gesamtzahl der Parameter in einem Modell gibt einen Hinweis auf die Komplexität und die Kapazität des Modells. Modelle mit mehr Parametern können in der Regel komplexere Muster in den Daten erkennen, benötigen aber auch mehr Daten und Rechenleistung für ein effektives Training. Obwohl kleinere Modelle bei komplexen Sprachaufgaben im Allgemeinen weniger effektiv sind als größere Modelle, haben Fortschritte in der Architektur und den Trainingstechniken ihre Effizienz und Wirksamkeit erheblich verbessert. Diese werden oft mit kuratierten, strukturierten und domänenspezifischen Daten trainiert und können deshalb für Teilbereiche sehr effektiv sein. Zudem kann durch verschiedene Methoden die Modellgröße reduziert werden, ohne die Leistung stark zu beeinträchtigen. Es gibt inzwischen eine Breite Palette von Small Language Models.
Fazit
Auch als kleines oder mittelständisches Unternehmen kann man mit KI automatisieren und Prozesse optimieren. Es kommt hier sehr stark darauf an, mit geringem Ressourcenverbrauch ein Modell zu trainieren, welches die eigenen Prozesse optimiert und dabei kosten- und zeiteffizient ist. Ein anderer Aspekt ist die Datenhoheit. Mit fertigen Cloud-Lösungen hat man evtl. schnell ein Modell trainiert, jedoch sind die Folgekosten meist höher und die Daten werden in die Cloud des jeweiligen Anbieters geladen. Damit verliert man einen Teil der Datenhoheit. Dies gilt natürlich bei jeder Cloud-Lösung und man kann daher über die Relevanz dieses Aspekts diskutieren. Hier spielen die großen Cloud Anbieter wie AWS, Microsoft oder Google eine spannende Rolle. Diese bieten auf ihren Infrastukturen Modelle an, die man feintunen kann. Die Modelle werden dann in der Infrastruktur des Cloudanbieters ausgeführt für den man sich evtl. schon entschieden hat und damit ist die Frage der Datenhoheit relativ einfach beantwortet. Jedoch lohnt es sich genau zu untersuchen, welche Modelle für den Anwendungsfall die richtigen sind, welche Ressourcen verbraucht werden und wie die Daten gehalten werden sollen. Damit sind auch für kleinere Unternehmen Lösungen für KI-Anwendungen wie z.B. Kundenanalyse, KI gestütztes Marketing und Social Media, Personalisierung der Nutzererfahrung, Vorhersageanalytik, Finanzmanagement und Prozessautomatisierung möglich.
In unserem nächsten Artikel werden wir uns detaillierter mit Small Language Models beschäftigen und welche Einsatzmöglichkeiten es hierfür gibt.